原文地址:http://www.onjava.com/pub/a/onjava/2006/10/04/what-is-java-content-repository.html?page=4
JSR-170把自己定义为一个能与内容仓库互相访问的,独立的,标准的方式。同时它也对内容仓库做出了自己的定义,它认为内容仓库是一个高级的信息管理系统,该系统是是传统的数据仓库的扩展,它提供了诸如版本控制、全文检索,访问控制,内容分类、访问控制、内容事件监视等内容服务。
Java Content Repository API(JSR-170)试图建立一套标准的API去访问内容仓库。如果你对内容管理系统(CMS)不熟悉的话,你一定会对内容仓库是什么感到疑惑。你可以这样去理解,把内容仓库理解为一个用来存储文本和二进制数据(图片,word文档,PDF等等)的数据存储应用程序。一个显著的特点是你不用关心你真正的数据到底存储在什么地方,是关系数据库?是文件系统?还是XML?不仅仅是数据的存储和读取,大多数的内容仓库还提供了更加高级的功能,例如访问控制,查找,版本控制,锁定内容等等。
一段时间以来市场上出现了各个厂家开发的不同的CMS系统,这些系统都建立在他们各自的内容仓库之上。
问题出现了,每个CMS开发商都提供了他们自己的API来访问内容仓库。这对应用程序的开发者带来了困扰,因为他们要学习不同的开发商提供的API,同时,他们的代码也与这些特定的API产生了绑定。
JSR-170正是为解决这一问题而出现的,它提供了一套标准的API来访问任何数据仓库。通过JSR-170,你开发代码只需要引用 javax.jcr.* 这些类和接口。它适用于任何兼容JSR-170规范的内容仓库。
我们将通过一个例子来逐步了解JSR-170。
为什么需要 Java Content Repository API
随着各个厂家各自的内容仓库实现数量的增长,人们越来越需要一组通用的编程接口来使用这些内容仓库,这就是JSR-170所要做的东西。它提供一组通用的编程接口来连接内容仓库。你可以把JSR-170理解为和JDBC类似的API,这样你可以不依赖任何具体的内容仓库实现来开发你的程序。你可以直接使用支持JSR-170的内容仓库;或者如果一些厂家的内容仓库不支持JSR-170则可以通过这些厂家提供的JSR-170驱动来完成从JSR-170与厂家特定的内容仓库的转换。
下面这张图描述了使用JSR-170开发的应用系统的结构。在该系统运行的时候,它可以操作内容仓库1,2,3中的任意一个。在这些内容仓库当中,只有2是直接支持JSR-170的,剩下的两个都需要JSR-170驱动来和应用系统交互。注意:你的应用系统完全不用关心你的数据是如何存储的。1可能使用了关系数据库来存储,而2使用了文件系统,至于上,它甚至更前卫的使用了XML。

JSR-170 API对不同的人员提供了不同的好处。
●对于开发者无需了解厂家的仓库特定的API,只要兼容JSR-170就可以通过JSR-170访问其仓库。
●对于使用CMS的公司则无需花费资金用于在不同种类CMS的内容仓库之间进行转换。
●对于CMS厂家,无需自己开发内容仓库,而专注于开发CMS应用。
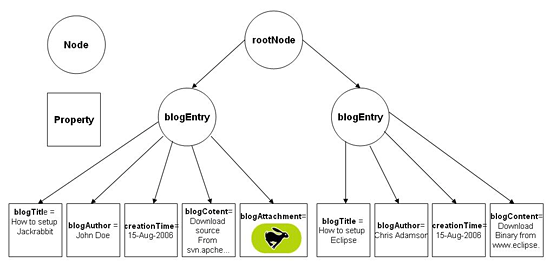
JSR-170 是这样定义内容仓库的,内容仓库由一组 workspace(工作空间)组成,这些workspace通常应该包含相似的内容。一个内容仓库有一个到多个 workspace。每个workspace都是一个树状结构,都有一个唯一的树根节点(root node)。树上的item(元素)或者是个node(节点)或者是个property(属性)。每个node都可以有零个到多个子节点和零个到多个子属性。只有根节点没有父节点,其余所有的节点都有一个父节点。property 也必须有一个父节点,但它没有子节点或是子属性,property 是叶子元素。property是真正存储数据的元素。
下图描述了一个blog应用程序的内容仓库模型。每个root node(根节点)的子节点都代表了一个blog实体。与这个blog实体有关的数据都存储在 bolgEntry 节点的属性里,其中一个 blogAttachment property 存储了一个二进制图片文件。
根据内容仓库实现的功能,JSR-170定义了三种级别:
Level 1:定义了一个只读的内容仓库。功能包括读取内容,将内容导出为XML和查找内容。
Level 2:定义了可写的内容仓库。Level 2是Level 1的扩展,新增的功能包括往内容仓库里写入内容,和从XML导入数据到仓库。
Advanced options:定义实现五种附加功能,版本控制、JTA、SQL查询、清晰的内容锁定和监视。
什么是Apache JackRabbit?
Apache JackRabbit是一个开放源码的JSR-170 实现,实现了Level 2,但它还有许多扩展的功能。详细可以去它的官方网站。
下面我们决定用Apache JackRabbit来作为我们示例程序的内容仓库。
如何配置Apache JackRabbit
JackRabbit需要两个参数来配置一个内容仓库实例。
1.内容仓库主目录:这个文件目录下通常包含了所有的内容,搜索索引,内部配置文件和其他持久化信息。它的结构看起来会像下面这个样子:
python 代码
- c:/temp
- |
- |--Blogging
- |
- |-repository
- | |
- | |-index
- | |-meta
- | |-namespaces
- | |-nodetypes
- |
- |-version
- |
- |-workspace
- |
- |--default
在上面的情况下,内容仓库主目录是c:/temp/Blogging.
2.内容仓库配置文件:一个典型的配置文件如下:
xml 代码
- <Repository>
- <FileSystem class="org.apache.jackrabbit.core.fs.local.LocalFileSystem">
- <param name="path" value="${rep.home}/repository"/>
- FileSystem>
- <Security appName="Jackrabbit">
- <AccessManager class="org.apache.jackrabbit.core.security.SimpleAccessManager"/>
- <LoginModule class="org.apache.jackrabbit.core.security.SimpleLoginModule">
- <param name="anonymousId" value="anonymous"/>
- LoginModule>
- Security>
- <Workspaces rootPath="${rep.home}/workspaces" defaultWorkspace="default"/>
- <Workspace name="${wsp.name}">
- <FileSystem class="org.apache.jackrabbit.core.fs.local.LocalFileSystem">
- <param name="path" value="${wsp.home}"/>
- FileSystem>
- <PersistenceManager
- class="org.apache.jackrabbit.core.state.db.DerbyPersistenceManager">
- <param name="url" value="jdbc:derby:${wsp.home}/db;create=true"/>
- <param name="schemaObjectPrefix" value="${wsp.name}_"/>
- PersistenceManager>
- <SearchIndex class="org.apache.jackrabbit.core.query.lucene.SearchIndex">
- <param name="path" value="${wsp.home}/index"/>
- SearchIndex>
- Workspace>
- <Versioning rootPath="${rep.home}/version">
- <FileSystem class="org.apache.jackrabbit.core.fs.local.LocalFileSystem">
- <param name="path" value="${rep.home}/version" />
- FileSystem>
- <PersistenceManager
- class="org.apache.jackrabbit.core.state.db.DerbyPersistenceManager">
- <param name="url" value="jdbc:derby:${rep.home}/version/db;create=true"/>
- <param name="schemaObjectPrefix" value="version_"/>
- PersistenceManager>
- Versioning>
- <SearchIndex class="org.apache.jackrabbit.core.query.lucene.SearchIndex">
- <param name="path" value="${rep.home}/repository/index"/>
- SearchIndex>
- Repository>
在这个配置文件里,<repository></repository>元素是根元素,它包含了下面这些元素:
a,<filesystem></filesystem>: 该元素配置了内容仓库的全局数据存储位置,这些全局数据包括已注册的命名空间,定制的节点类型等等。 JackRabbit 提供了几种选择,一种是像上面例子里配置的存储在本地文件里,LocalFileSystem. 如果你想把它们存储在数据库里,你可以使用 DbFileSystem.
b,<security></security>:内容仓库的安全配置,它有两个子元素:<accessmanager></accessmanager>和<loginmodule></loginmodule>。<accessmanager></accessmanager>配置的类用来判断用户有没有权限来对特定数据执行特定的操作。
c,<workspaces></workspaces>:这个元素的配置对所有的workspace都通用。它的rootPath 属性是所有workspace文件夹的根目录,在我们的例子里它是c:/temp/Blogging/Workspace;defaultWorkspace 属性则包含了workspace的默认名。
d,<workspace></workspace>:这个元素是所有workspace的默认配置模板。去每个workspace文件夹下你都会发现一个workspace.xml文件,这个文件和这个元素的配置一模一样。三个子元素:<filesystem></filesystem>,和这个workspace相关数据的存储位置;
<persistencemanager></persistencemanager>
,这个workspace内容节点存储策略;<searchindex></searchindex>,可选,全文检索。
e,<versioning></versioning>:配置一个版本相关的对象。其实JackRabbit也是把它作为节点来处理的。
这两个参数可以通过两种方式设置,一种是在仓库实例创建时直接传到Jackrabbit里去,一种是间接的通过设置JNDI object factory。
你可以设置org.apache.jackrabbit.repository.home 这个系统属性的值来指定你的内容仓库主目录;也可以设置
org.apache.jackrabbit.repository.conf 这个系统属性的值来指定你的内容仓库配置文件repository.xml。如果你不设定这两个
参数,Jackrabbit会把当前目录作为内容仓库主目录,同时,它有一个默认的内容仓库配置文件。
开发我们的例子程序
jackrabbit已经配置好了,现在让我们来创建我们的示例程序。这个例子程序将调用JCR-170 API。很显然,我们需要做两件事情:一个是作为后台的对数据进行增删改查(持久层),另一个是开发相对应的UI界面(WEB 层)。首先,让我们定义一个DAO接口。这个接口BlogEntryDAO.java 如下:
java 代码
- public interface BlogEntryDAO {
- public void insertBlogEntry(BlogEntryDTO blogEntryDTO)
- throws BlogApplicationException;
- public void updateBlogEntry(BlogEntryDTO blogEntryDTO)
- throws BlogApplicationException;
- public ArrayList getBlogList()
- throws BlogApplicationException;
- public BlogEntryDTO getBlogEntry(String blogTitle)
- throws BlogApplicationException;
- public void removeBlogEntry(String blogTitle)
- throws BlogApplicationException;
- public ArrayList searchBlogList(String userName)
- throws BlogApplicationException;
- public void attachFileToBlogEntry(String blogTitle, InputStream uploadInputStream)
- throws BlogApplicationException;
- public InputStream getAttachedFile(String blogTitle)
- throws BlogApplicationException;
- }
正如你看到的,这个接口提供了增删改查的方法,同时还提供了两个方法来处理附件。接下来,我们需要一个DTO对象用来在两个层之间传递数据。
java 代码
- public class BlogEntryDTO {
-
- private String userName;
- private String title;
- private String blogContent;
- private Calendar creationTime;
-
-
- }
这里我们将仅仅讨论持久层。
连接jackrabbit
现在,第一件事情是开发一个组件,获得一个到jackrabbit内容仓库的连接。为了简单,我们将在程序启动的时候获得这个连接,然后在程序停止的时候释放这个连接。这里我们使用了Struts ,所以我们需要开发一个PlugIn 类。如下:
java 代码
- public class JackrabbitPlugin implements PlugIn{
- public static Session session;
- public void destroy() {
- session.logout();
- }
- public void init(ActionServlet actionServlet, ModuleConfig moduleConfig)
- throws ServletException {
- try {
- System.setProperty("org.apache.jackrabbit.repository.home",
- "c:/temp/Blogging");
- Repository repository = new TransientRepository();
- session = repository.login(new SimpleCredentials("username",
- "password".toCharArray()));
- } catch (LoginException e) {
- throw new ServletException(e);
- } catch (IOException e) {
- throw new ServletException(e);
- } catch (RepositoryException e) {
- throw new ServletException(e);
- }
- }
- public static Session getSession() {
- return session;
- }
- }
init()方法将会在程序启动的时候调用,destroy()将会在程序停止的时候调用。我们在init()方法里获得了到jackrabbit内容仓库的连接。看看代码,我们做的第一件事是设定了org.apache.jackrabbit.repository.home这个系统属性,在上篇文章里提到,这个属性是用来指向我们的内容仓库主目录。这里我们设定它为c:/temp/blogging。接下来,我们创建了TransientRepository的一个实例。这是jackrabbit提供的类,它提供了一个到内容仓库的代理。它在第一个session 打开的时候自动启动内容仓库,在最后一个session 关闭的时候自动关闭内容仓库。
一旦我们获得了一个内容仓库对象,我们就可以调用它的login() 方法来打开一个连接。login() 方法需要一个Credential 对象作为参数。如果Credential 对象是NULL,jackrabbit会认为其他的机制做了这个验证(比如JAAS)。login() 方法还可以传入一个workspace名字作为参数,如果不传入这个参数,jackrabbit会返回一个session对象指向默认的workspace。注意workspace和session是一对一的,即一个session仅对应一个workspace。(注:如果不传入Credential对象,返回的session对workspace是只读的)
增加内容
连接已经建立起来了,下面让我们实现BlogEntryDAO这个接口。第一个我们想实现的方法是插入数据 insertBlogEntry():
java 代码
- public void insertBlogEntry(BlogEntryDTO blogEntryDTO)
- throws BlogApplicationException {
- Session session = JackrabbitPlugin.getSession();
- Node rootNode = session.getRootNode();
- Node blogEntry = rootNode.addNode("blogEntry");
- blogEntry.setProperty("title", blogEntryDTO.getTitle());
- blogEntry.setProperty("blogContent", blogEntryDTO.getBlogContent());
- blogEntry.setProperty("creationTime", blogEntryDTO.getCreationTime());
- blogEntry.setProperty("userName", blogEntryDTO.getUserName());
- session.save();
- }
首先获得session 对象,即到内容仓库特定workspace的连接。然后,我们在这个session 对象上调用getRootNode() 方法,获得这个workspace的根节点,这个根节点的路径是("/").一旦我们获得这个根节点,我们就可以通过addNode()方法在这个根节点下增加新的子节点。新节点的名字是blogEntry. 通过setProperty() 方法我们把数据存储到节点的property里。正如我们先前说明的,真实的数据是存储在property元素里,property元素是叶子。
注意session.save() 这行代码。这个方法是必须调用的,这个方法调用之前,任何 Node,Property的改变都被保存在这个session的一个临时区域里,其他的和该session连接到相同workspace的session都看不到这些改变。当这个方法被调用并被成功执行后,这些Node,Property的改变才会被持久化到这个session关联的workspace里,同时所有与这个workspace关联的session才可见这些变化。相对应的,Session.refresh(false)将会丢弃所有这些改变。item.save()和Item.refresh(false)作用相似,只是影响范围限定在单个Item上(注意,包括它的子节点)
获得列表
在上一步中我们已经把数据保存到了内容仓库中,那我们如何确定数据确实保存进去了呢?getBlogList() 这个方法将返回根节点下所有名为blogEntry.的子节点。
java 代码
- public ArrayList getBlogList() throws BlogApplicationException {
- Session session = JackrabbitPlugin.getSession();
- ArrayList blogEntryList = new ArrayList();
- Node rootNode = session.getRootNode();
- NodeIterator blogEntryNodeIterator = rootNode.getNodes();
-
- while (blogEntryNodeIterator.hasNext()) {
- Node blogEntry = blogEntryNodeIterator.nextNode();
- if (blogEntry.getName().equals("blogEntry") == false)
- continue;
- String title = blogEntry.getProperty("title").getString();
- String blogContent = blogEntry.getProperty("blogContent").getString();
- Value creationTimeValue = (Value) blogEntry.getProperty(
- "creationTime").getValue();
- String userName = blogEntry.getProperty("userName").getString();
- BlogEntryDTO blogEntryDTO = new BlogEntryDTO(userName, title,
- blogContent, creationTimeValue.getDate());
- blogEntryList.add(blogEntryDTO);
- }
- return blogEntryList;
- }
一旦你获得了根节点这个对象,你就可以通过调用getNodes()这个方法来获取它所有的子节点。如果这个节点没有子节点,将返回一个空的NodeIterator 对象。我们可以遍历这个NodeIterator 对象来获得名为blogEntry 的节点集合,然后通过getProperty()方法来获得节点上的属性,即我们保存的真实数据。getProperty()方法返回Value对象的一个实例。因为存储数据类型的不同,所以返回的Value对象实例是不同的。根据不同的数据类型,你应该调用特定的方法来获取数据,比如getString()来获取字符串,而getDate()获得一个日期。
查找内容(用XPath的方式)
JSR-170定义了两种方式来查找内容(也可以理解为查找节点)。一种使用XPath语法,另一种使用SQL语法。JSR-170要求Level 1必须实现XPath的方式,而SQL的方式则作为一个可选的功能。
XPath原本是一种设计用来查找XML元素的语言。因为我们的workspace是树状的结构,很像XML。所以XPath语法非常适合于在这里查找内容。下面的代码演示了通过作者名来查找节点。
java 代码
- Session session = JackrabbitPlugin.getSession();
- Workspace workSpace = session.getWorkspace();
- QueryManager queryManager = workSpace.getQueryManager();
-
- StringBuffer queryStr = new StringBuffer(
- "//blogEntry[@"+PROP_BLOGAUTHOR +"= '");
- queryStr.append(userName);
- queryStr.append("']");
- Query query = queryManager.createQuery(queryStr.toString(),
- Query.XPATH);
-
- QueryResult queryResult = query.execute();
-
- NodeIterator queryResultNodeIterator = queryResult.getNodes();
- while (queryResultNodeIterator.hasNext()) {
-
- Node blogEntry = queryResultNodeIterator.nextNode();
- String title = blogEntry.getProperty(PROP_TITLE).getString();
- String blogContent = blogEntry.getProperty(PROP_BLOGCONTENT).getString();
- Value creationTimeValue = (Value) blogEntry.getProperty(
- PROP_CREATIONTIME).getValue();
- BlogEntryDTO blogEntryDTO = new BlogEntryDTO(userName, title,
- blogContent, creationTimeValue.getDate());
- blogEntryList.add(blogEntryDTO);
- }
分享到:





相关推荐
那么,到底什么是JCR,其中又包含哪些内容呢? 首先,是JCR的收录范围。 JCR创办之初,仅包含SCI期刊,后来陆续引入SSCI和AHCI期刊。2021年发布的2020JCR首次引入了ESCI期刊的数据。因此,虽然目前SCI和SSCI数量为...
JCR的2.0版规范
ISI每年出版JCR(《期刊引用报告》,全称Journal Citation Reports)。JCR对包括SCI收录的3800种核心期刊(光盘版)在内的8000多种期刊(网络版)之间的引用和被引用数据进行统计、运算,并针对每种期刊定义了影响因子...
JCR分区表,助力科研,很有用的啊 ,Excel格式很有参考价值
中科院2015年JCR分区与SCI影响因子
JCR官方说明文档.doc
JCR 开发文档,详细描述JCR的API
2022年JCR正式发布(附最新影响因子名单) 重磅!2022年JCR正式发布(附最新影响因子名单,前600) 重磅!2022年JCR正式发布(附最新影响因子名单) 重磅!2022年JCR正式发布(附最新影响因子名单) 重磅!2022年JCR...
JCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JAR
标签:abdera-jcr-1.0.jar,abdera,jcr,1.0,jar包下载,依赖包
JSR-170 API jcr-1.0.jar
2019JCR期刊分区表,分区分为四种Q1、Q2、Q3、Q4,包含了大多数国外期刊,需要的自行下载查找
modeshape源码,用的人很少,但是modeshape绝对是精髓啊~!
jcr_in_action.pdf
Content Repository for Java Technology API 1.0
按年度通过 刊名/简称/ISSN进行查询,需要联网。 数据来源为 “中科院文献情报中心期刊分区表开放平台” 查询结果示例: 期刊名称: IMAGE AND VISION COMPUTING +------+------------------+------+ ...
自创手写。 满足以下条件即可参考: 1. maven的java工程,至少明白maven的机制 2. CQ5服务器,知道CQ5 3. 使用javax.jcr 以上为简单入门教程,复杂技能请自己修行。
2017年jcr最新收录情况,这里有最新的SCI期刊及其影响因子,快来看看你发的论文属于什么水平吧。2017年jcr最新收录情况,这里有最新的SCI期刊及其影响因子,快来看看你发的论文属于什么水平吧。
国内很多时候都很看重这个JCR分区表,希望对大家有所帮助!!欢迎多多下载,谢谢!
信息检索资料 SCIE JCR 使用指南 信息检索